第一篇 问题阐述
我有一个看似很简单的任务:“有一个从后端检索的数据集,其中包含13,000个数据项,每一项都是冗长罗嗦的名称(科学组织)。使用这些数据创建一个带自动补齐功能的搜索栏。”
你也不觉得很难,对不对?
难点1:
不能使用后端。后端只能提供原始的数据集,所有搜索逻辑都必须在前端完成。
难点2:
开发人员(我):“这些组织名称这么长,需要花点心思。如果我们只是运行简单的字符串匹配,而且用户可能会输错或出现拼写错误,那么就很难搜索到任何结果。”
客户:“你说的对,我们必须加入一些智能的功能,预测用户的输入,忽略输入的错别字。”
注意:一般情况下,我不建议你在未经项目经理同意下,提示客户没有提到的复杂功能!这种情况称为特征蔓延(feature creep)。在上述例子中,只是恰巧我一个人负责这个合同,我有足够的精力,所以我认为这是一个有趣的挑战。
难点3:
这是最大的难点。我选择的智能(也称为“模糊”)搜索引擎非常慢……
随着搜索词的长度加长,这个搜索算法库的搜索时间会迅速增加。此外,看看下面这个庞大的列表,里面的数据项极其冗长,用户需要输入一个很长的搜索词才能出现自动补齐提示。别无他法,搜索引擎跟不上用户的打字速度,这个UI可能会废掉。
我不知道是不是因为我选择的这个搜索算法库太过糟糕,我也不知道是不是因为所有“模糊”搜索算法都是这样的情形。但幸运的是,我没有费心去寻找其他选择。
尽管上述难点大多数是我自己强加上去的,但我依然决定坚持到底,努力优化这种实现。虽然我知道这可能不是最佳策略,但是这个项目的情况允许我这么做,结果将说明一切,最重要的是,对我来说这是一次绝佳的学习体验和成长的机会。
第二篇 问题剖析
在第一个实现中,我使用了UI的react-autocomplete和react-virtualized库。
render () {
return (
<Autocomplete
value={this.state.searchTerm}
items={this.getSearchResults()}
renderMenu={this.reactVirtualizedList}
renderItem={this.renderItem}
getItemValue={ item => item.name }
onChange={(e, value) => this.setState({searchTerm: value})}
/>
)
}
Autocomplete组件需要传递以下几项:value属性,需要传入输入框中的searchTeam;items属性,传入搜索结果;以及renderMenu函数,该函数将搜索结果列表传递给react-vertualized。
react-virtualized能够很好地处理大型列表(它只会渲染列表显示在屏幕上的一小部分,只有滚动列表时才会更新)。考虑到我们需要渲染的组件并不多,我认为应该不会有太严重的性能问题。
更新操作的声明周期也很简单:
- 用户输入’a’
- Autocomplete的onChange处理函数触发一次渲染,此时this.state.searchTeam = ‘a’
- 该渲染会调用getSearchResults方法,在这个方法中,搜索引擎使用’a’作为搜索关键字计算搜索结果,然后将结果传递给react-virtualized负责渲染。
getSearchResults = () => {
const {searchTerm} = this.state;
return searchTerm ? this.searchEngine.search(searchTerm) : []
// searchEngine.search is the expensive search algorithm
};
我们来看看结果如何:
哎呀……很糟。在按住删除键时的的确确能感觉到UI的停顿,因为键盘触发delete事件太快了。
不过至少模糊搜索好用了:’anerican’正确地解释成了’American’。但随着搜索关键字的加长,两个元素(输入框和搜索结果)的渲染过程完全跟不上用户输入的速度,延迟非常大。
尽管我们的搜索算法的确很慢,但如此大的延迟并不是由于单次搜索时间太长导致的。这里还有另外一个现象需要理解:我们管它叫UI阻塞。理解这个现象需要深入了解Chrome的DevTools性能评测工具。
性能评测
可能你不熟悉这个工具,但是你要知道,熟练使用性能评测工具是深入理解JavaScript的最好方式。这不仅因为它能提供有用的信息帮你解决各种问题,而且按照时间显示出JavaScript的执行过程能够帮助你更好地理解好的UI、React、JavaScript事件循环、同步异步执行等概念。
在下面每一节,我都会给出性能分析过程,以及从这些过程中推断出的有趣的结论。这些数据可能会让你眼花缭乱,但我会尽力给出合理的解释!
首先评测一下在Autocomplete中按下两个键时的情况:
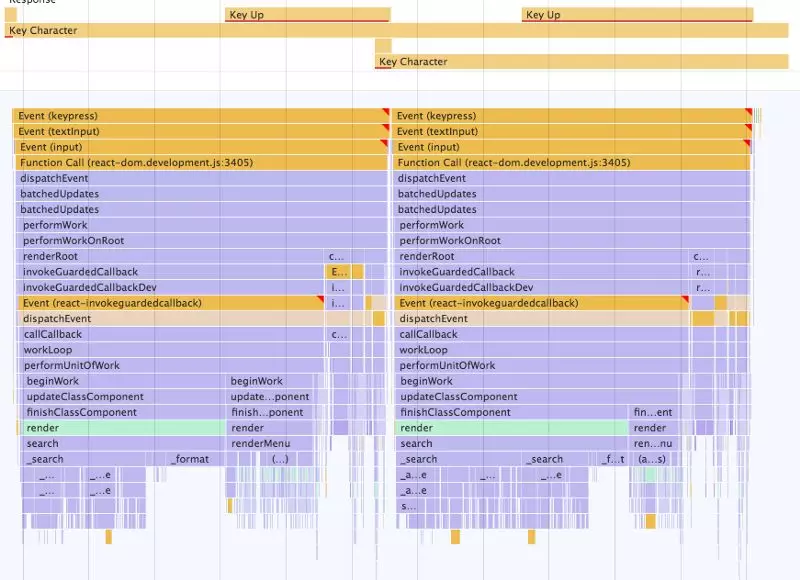
X轴:时间,Y轴:按照类型排列的事件(用户输入、主线程函数调用)
理解基本的序列非常重要:
首先是用户的键盘输入(Key Characer)。这些输入在JavaScript的主线程上触发了Event(keypress)事件,该事件又触发了我们的onChange处理函数,该函数会调用setState(图上看不见,因为它太小了,但它的位置在整个栈的最开头附近)。这一系列动作标志着重新计算的开始,计算setState对组件会产生何种影响。这一过程称为更新,或者叫做重新渲染,它会调用几个React生命周期方法,其中就包括render。这一切都发生在一个执行栈(有时称为“调用栈”或简称为“栈”),在图中由每个Event (keypress)下方竖直排列的框表示。每个框都是执行栈中的一次函数调用。
这里不要被render这个词误导了。React的渲染并不仅仅是在屏幕上绘制。渲染只是React用来计算被更新的元素应当如何显示的过程。如果仔细查看第二个Event (keypress),就会发现在Event (keypress)框的外面有个小得几乎看不见的绿条。放大一些就能看到这是对浏览器绘制的调用:


这才是UI更新被真正绘制到屏幕上,并在显示器上显示新帧的过程。而且,第一个Event (keypress)之后没有绘制,只有第二个后面才有。
这说明,浏览器绘制(外观上的更新)并不一定会在Event (keypress)事件发生并且React完成更新之后发生。
原因是JavaScript的事件循环和JavaScript对于任务队列的优先级处理。在React结束计算并将更新写入DOM之后(称为提交阶段,发生在每个执行栈末尾的地方),你可能会以为浏览器应该开始绘制,将DOM更新显示在屏幕上。但是在绘制之前,浏览器会检查JavaScript事件队列中是否还有其他任务,有的任务会比绘制更优先执行。
当JavaScript线程忙于渲染第一个keypress时,产生第二个用户输入(如键盘按下事件)就会出现这种情况(你可以看到第二个Key Character输入发生在第一个keypress执行栈依然在运行时)。这就是前面提到的UI阻塞。第二个Event (keypress)阻塞了UI更新第一个keypress。
不幸的是,这会导致巨大的延迟。因为渲染本身非常慢(部分原因是因为渲染中包含了昂贵的搜索算法),如果用户输入非常快,那么很大可能会在前一个执行栈结束之前输入新的字符。这会产生新的Event (keypress),并且它的优先级比浏览器绘制要高。所以绘制会不断被用户的输入拖延。
不仅如此,甚至在用户停止输入后,队列中依然滞留了许多keypress时间,React需要依次对每个keypress进行计算。所以,即使在输入结束后,也不得不等待这些针对早已不需要的searchTeams的搜索!

注意最后一个Key Character发生后,还有4个Event (keypress)滞留,浏览器需要处理完所有事件才能重绘。
改进方法
为了解决这个问题,重要的是要理解好的UI的要素是什么。实际上,对于每次键盘输入,用户期待的视觉反馈包括两个独立的要素:
- 用户输入的键显示在输入框中;
- 搜索结果根据新的searchTeam进行更新。
理解用户的期望才能找到解决方案。尽管Google搜索快得像闪电一样,但用户无法立即收到搜索结果的事情也屡见不鲜。一些UI甚至会在请求搜索结果时显示加载进度条。
重要的是要理解,对于反应迅速的UI而言,第一种反馈(按下的键显示在输入框中)扮演了非常重要的角色。如果UI无法做到这一点,就会有严重的问题。
查看性能评测是解决问题的第一个提示。仔细观察这些长长的执行栈和render中包含的昂贵的search方法,我们会发现,更新输入框和搜索结果的一切操作都发生在同一个执行栈内。所以,两者的UI更新都会被搜索算法阻塞。
但是,输入框的更新不需要等待结果!它只需要知道用户按下了哪个键,而不需要知道搜索结果是什么。如果我们有办法控制事件执行的顺序,输入框就有机会先更新UI,再去渲染搜索结果,这样就能减少一些延迟。因此,我们的第一个优化措施就是将输入框的渲染从搜索结果的渲染中分离出来。
注意:熟悉Dan Abramov在React JSConf 2018上的演讲的人应该能回忆起这个场景。在他的幻灯片中,他设计了一个昂贵的更新操作,随着输入值的增加,屏幕上需要渲染的组件也越来越多。这里我们遇到的困难非常相似,只不过是随着搜索关键字长度的增加,单个搜索函数的复杂度会增加而已。在Dan的演讲中,他演示了时间切片(Time Slicing),这个React团队在开发中的功能也许可以解决这个问题!我们的尝试会以相似的方案解决问题:找到一个方法来改变渲染的顺序,防止昂贵的计算再次阻塞主线程的UI更新。
第三篇 异步渲染(componentDidUpdate)
注意:本篇讨论的优化最后以失败告终了,但我认为值得讲一讲,因为它能帮助我们更好地理解React的componentDidUpdate生命周期。如果你非常熟悉React,或者只想看看怎样改善性能问题,那么可以直接跳到下一篇。
拆分组件
由于我们想把昂贵的搜索结果更新从输入框更新中拆分出来,所以我们应该自己设计一个组件,并放弃使用react-autocomplete库提供的一站式解决方案Autocomplete:
//autocomplete.js
render () {
return (
<div>
<input
onChange={ e => this.setState({searchTerm: e.target.value})}
value={this.state.searchTerm}/>
<SearchResults
searchEngine={this.props.searchEngine}
searchTerm={this.state.searchTerm}/>
</div>
)
}
然后在SearchResults中,我们需要异步触发searchEngine.search(searchTerm),而不应该在更新searchTerm的同一个渲染中进行。
我最初的想法是利用SearchResults的componentDidUpdate,让searchEngine异步工作,因为听上去这个方法似乎是在更新之后异步执行的。
//searchResults.js
componentDidUpdate(prevProps) {
const {searchTerm, searchEngine} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
this.setState({
searchResults: searchEngine.search(searchTerm)
})
}
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
我们将昂贵的searchEngine移动到了componentDidUpdate中,这样就不用在render方法中调用,而是等到更新之后再执行。我希望在输入框更新之后的另一个执行栈中执行render,并两者之间执行一次绘制。我想象的新的更新生命周期如下:
- 输入框使用新的searchTerm渲染;
- React把带有新的searchTerm的componentDidUpdate searchEngine任务放入队列;
- 浏览器绘制输入框的更新,然后处理队列中的searchEngine任务。理论上,浏览器不会把这个任务放在绘制任务之前,因为它不涉及用户交互事件;
- componentDidUpdate在输入框绘制之后执行,计算搜索结果并生成新的更新。
很不幸,认为componentDidUpdate会在浏览器更新之后运行是一个常见的误解。我们来看看这个方法的性能评测:
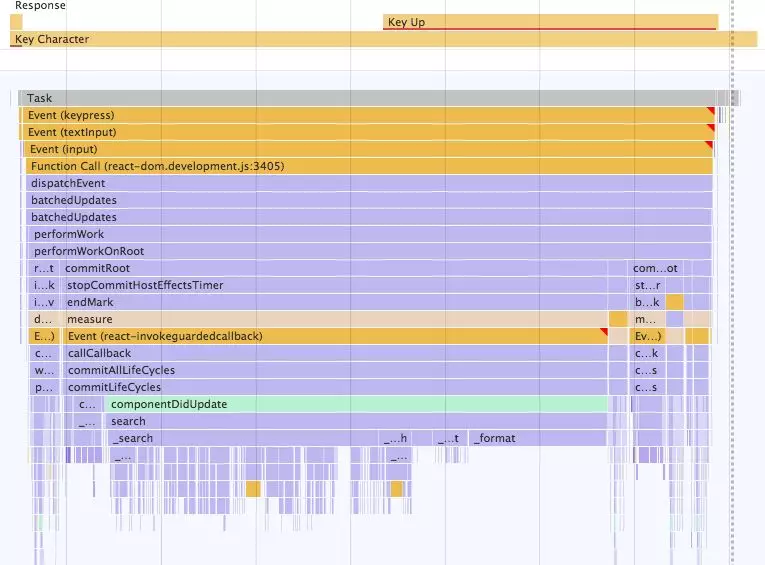
看到问题了吗?componentDidUpdate跟最初的keypress事件是在同一个执行栈上执行的
componentDidUpdate并不会在绘制结束后执行,因此执行栈跟上一篇一样昂贵,我们只不过是将昂贵的search方法移动到了不同位置而已。尽管这个解决方案并不能改善性能,但我们可以借此机会理解React的生命周期componentDidUpdate的具体行为。
虽然componentDidUpdate不会在另一个执行栈上运行,但它确实是在React更新完组件状态并将更新后的DOM值提交之后才执行的。尽管这些更新后的DOM值还没有被浏览器绘制,它们依然反映了更新后的UI应有的样子。所以,任何componentDidupdate内执行的DOM查询都能访问到更新后的值。所以,组件确实更新了,只是浏览器中看不见而已。
所以,如果想要做DOM计算,一般都应该在componentDidUpdate中进行。在这里很方便根据布局改变进行更新,比如根据新的布局方式计算元素的位置或大小,然后更新状态等。
如果componentDidUpdate每次触发改变布局的更新时都要等待实际的浏览器绘制,那么用户体验会非常糟糕,因为用户可能会在布局改变时看到两次屏幕闪烁。
注(React Hooks):这个差异也有助于理解新的useEffect和useLayoutEffect钩子。useEffect就是我们在这里尝试实现的效果。它会让代码在另一个执行栈中运行,从而在执行之前浏览器可以进行绘制。而useLayoutEffect更像是componentDidUpdate,允许你在DOM更新之后、浏览器绘制之前执行代码。
第四篇 异步渲染(setTimeout)
上一篇我们拆分了组件:
//autocomplete.js
render () {
return (
<div>
<input
onChange={ e => this.setState({searchTerm: e.target.value})}
value={this.state.searchTerm}/>
<SearchResults
searchEngine={this.props.searchEngine}
searchTerm={this.state.searchTerm}/>
</div>
)
}
但我们没能让昂贵的searchEngine在另一个执行栈上运行。那么,还有什么办法能实现这一点呢?
有两个常见的方法可以设置异步调用:Promise和setTimeout。
Promise
//searchResults.js
componentDidUpdate(prevProps) {
const {searchTerm, searchEngine} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
/* stick the update with the expensive search method into
a promise callback: */
Promise.resolve().then(() => {
this.setState({
searchResults: searchEngine.search(searchTerm)
})
})
}
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
我们来看看性能评测:
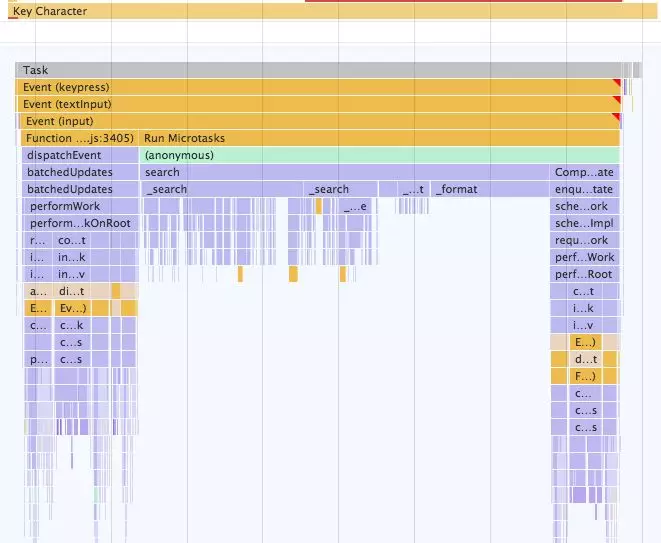
(anonymous)是Promise.then()回调函数
又失败了!
理论上Promsie的回调函数是异步的,因为它们不会同步执行,但实际上还是在同一个执行栈中运行的。
仔细看看性能评测就会发现,回调函数被放在了Run Microtasks下,因为Promise的回调函数被当作了微任务。浏览器通常会在完成正常的栈之后检查并运行微任务。
更多信息:Jake Archibald有一篇非常好的演讲(https://medium.com/r/?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DcCOL7MC4Pl0),解释了JavaScript事件循环在微任务方面的处理,还深入讨论了许多我涉及到的话题。
尽管了解这一点很好,但并没有解决问题。我们需要新的执行栈,这样浏览器才有机会在新的执行栈开始之前进行绘制。
setTimeout
//searchResults.js
componentDidUpdate(prevProps) {
const {searchTerm, searchEngine} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
/* stick the update with the expensive search method into
a setTimeout callback: */
const setTimeoutCallback = () => {
this.setState({
searchResults: searchEngine.search(searchTerm)
})
}
setTimeout(setTimeoutCallback)
}
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
性能评测:
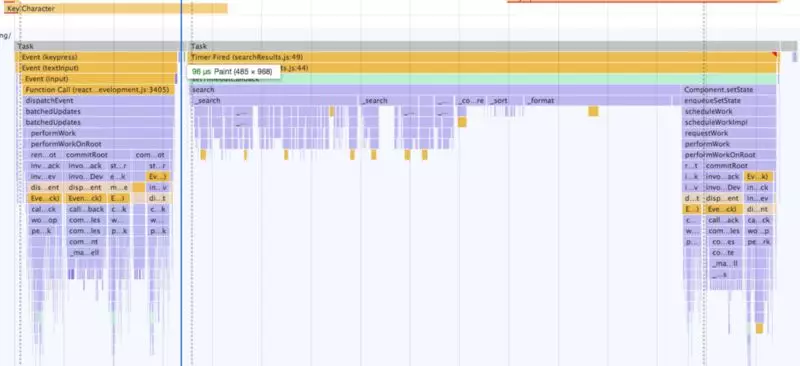
绘制很难看到,它太小了,但蓝线的位置的确发生了绘制
哈哈!成功了!注意到这里有两个执行栈:Event (keypress)和Timer Fired (searchResults.js:49)。两个栈之间发生了一次绘制(蓝线的位置)。这正是我们想要的!来看看漂亮的UI!

按住删除键时依然有明显的延迟
有很大的改进,但依然很令人失望……这个页面的确变好了,但依然能感觉到UI的延迟。我们来仔细看看性能测试。
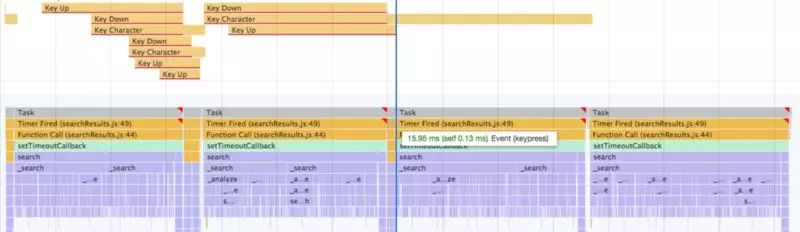
我们需要一些技巧才能分析这个性能测试报告并找出延迟的原因。使用性能报告有几个小技巧:
性能评测工具着重显示了两个特别有用的Key Input Interactions,每个都有不同的性能度量:
- Key Down:从键盘按下到Event (keypress)处理函数被调用的时间间隔;
- Key Character:从键盘按下到浏览器绘制更新的时间间隔。
理想状态下,Key Down交互应该非常短,因为如果JavaScript主线程没有被阻塞的话,事件应该在键盘按下之后立即出发。所以,看到长长的Key Down就意味着发生了UI阻塞问题。
在本例中,长长的Key Down的原因是它们触发时,主线程还在被昂贵的setTimeoutCallback阻塞,比如最后的Key Down。很不幸,Key Down发生时,运行昂贵的search的setTimeoutCallback刚刚开始,也就是说,Key Down只有等待search的计算结束才能触发事件。这个评测中的search方法大约花了330毫秒,也就是1/3秒。从优秀的UI角度而言,1/3秒的主线程阻塞实在太长了。
特别引起我注意的是最后一个Key Character。尽管它关联了Key Down的结束并且触发了Event (keypress),浏览器并没有绘制新的searchTerm,而是执行了另一个setTimeoutCallback。这就是Key Character交互花了两倍时间的原因。
这一点着实让我大跌眼镜。将search移动到setTimeoutCallback的目的,就是让浏览器能够在调用setTimeoutCallback之前进行绘制。但是在最后的Event (keypress)之前依然没有绘制(蓝线的位置)。
结论是,我们不能依赖于浏览器的队列机制。显然浏览器并不一定将绘制排在超时回调之前。如果超时回调需要占用主线程330毫秒,那么也会阻碍主线程,导致延迟。
第五篇 多线程
在上一篇中,我们拆分了组件,并成功地使用setTimeout将昂贵的search移动到了另一个执行栈中,因此浏览器无需等待 search完成,就可以绘制输入框的更新:
//autocomplete.js
render () {
return (
<div>
<input
onChange={ e => this.setState({searchTerm: e.target.value})}
value={this.state.searchTerm}/>
<SearchResults
searchEngine={this.props.searchEngine}
searchTerm={this.state.searchTerm}/>
</div>
)
}
//searchResults.js
componentDidUpdate(prevProps) {
const {searchTerm, searchEngine} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
const setTimeoutCallback = () => {
this.setState({
searchResults: searchEngine.search(searchTerm)
})
}
setTimeout(setTimeoutCallback)
}
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
不幸的是,这依然没有解决每个searchTerm导致search阻塞主线程330毫秒并导致UI延迟的问题。
JavaScript的单线程实在太糟糕了……突然我想到了一个方法。
最近我在阅读渐进式Web应用,其中有人使用Service Worker来实现一些过程,比如在另一个线程中进行缓存。于是我开始学习Service Worker。这是一个全新的API,我需要花点时间来学习。
但在学习之前我想先通过实验来验证一下增加额外的线程是否真的能够提高性能。
用服务器端来模拟第二个线程
我以前就做过搜索和自动补齐提示的功能,但这次特别困难的原因是需要完全在前端实现。以前我做过用API来获取搜索结果。其中一种思路是,API和运行API的服务器实际上相当于前端应用利用的另一个线程。
于是,我想到可以做一个简单的node服务器让searchTerm访问,从而实现在另一个线程中运行昂贵的搜索。这个功能非常容易实现,因为这个项目中已经设置过开发用的服务器了。所以我只需添加一个新的路径:
app.route('/prep-staging/testSearch')
.post(bodyParser.json(), (req, res) => {
const {data, searchTerm} = req.body
const engine = new SearchEngine(data)
const searchResults = engine.search(searchTerm)
res.send({searchResult})
})
然后将SearchResults中的setTimeout改成fetch:
//searchResults.js
componentDidUpdate(prevProps) {
const {searchTerm, searchEngine, data} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
/* ping the search route with the searchTerm and update state
with the results when they return: */
fetch(`testSearch`, {
method: 'POST',
body: JSON.stringify({data, searchTerm}),
headers: {
'content-type': 'application/json'
}
})
.then(r => r.json())
.then(resp => this.setState({searchResults: resp.searchResults}))
}
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
现在是见证奇迹的时刻!

注意看删除!
太棒了!输入框的更新几乎非常完美。而另一方面,搜索结果的更新依然非常缓慢,但没关系!别忘了我们的首要任务就是让用户在输入时尽快获得反馈。我们来看看性能测试报告:
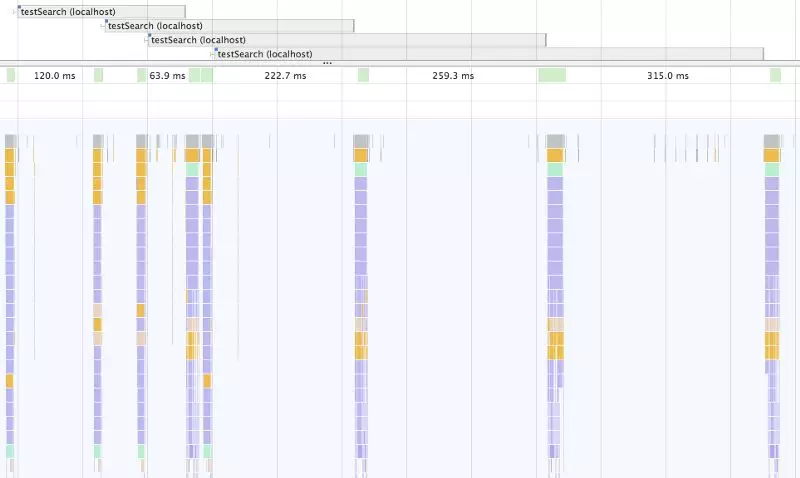
注意主线程中间漂亮的空白,它不再是之前层层叠叠的样子了。性能优化中经常会遇到这种情况。主线程中的空白越多越好!
从顶端可以看到testSearch花费的时间。最长的一个实际上花了800毫秒,让我很吃惊,但仔细想想就会发现,并不是search花了这么长时间,而是我们的Node服务器也是单线程的。它在第一个搜索完成之前无法开始另一个搜索。由于输入比搜索快得多,所以搜索会进入队列然后被延迟。搜索函数实际花费的时间是前一个搜索完成之后的部分,大约315毫秒。
总的来说,将昂贵的任务放到服务器线程中,就可以将堆叠的栈移动到服务器上。所以,尽管依然有改进的空间,但主线程看起来非常好,UI的响应速度也更快了!
我们已经证明这个思路是正确的,现在来实现吧!
做了一点研究后我发现,Server Worker并不是正确的选择,因为它不兼容Internet Explorer。幸运的是,它还有个近亲,叫做Web Worker,能兼容所有主流服务器,API更简单,而且能完成我们需要的功能!
第六篇 Web Worker
Web worker能够在JavaScript的主线程之外的另一个线程上运行代码,每个Web worker都由一个脚本文件启动。启动方式非常简单:
//searchResults.js
export default class SearchResults extends React.Component {
constructor (props) {
super();
this.state = {
searchResults: [],
}
//initiate the webworker:
this.webWorker = new Worker('...path to webWorker.js')
//pass it the 13,000 item search data to initialize the searchEngine with:
this.webWorker.postMessage({data: props.data})
//assign the handler that will accept the searchResults when it sends them back:
this.webWorker.onmessage = this.handleResults
}
componentDidUpdate(prevProps) {
const {searchTerm} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
//change our async search request to a .postMessage, the messaging API of webWorkers:
this.webWorker.postMessage({searchTerm})
}
}
handleResults = (e) => {
const {searchResults} = e.data
this.setState({
searchResults
})
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
}
下面是webWorker.js脚本,在SearchResults的构造函数中进行初始化:
//webWorker.js
self.importScripts('...the search engine script, provides the SearchEngine constructor');
let searchEngine;
let cache = {}
//thought I would add a simple cache... Wait till you see those deletes now :)
function initiateSearchEngine (data) {
//initiate the search engine with the 13,000 item data set
searchEngine = new SearchEngine(data);
//reset the cache on initiate just in case
cache = {};
}
function search (searchTerm) {
const cachedResult = cache[searchTerm]
if(cachedResult) {
self.postMessage(cachedResult)
return
}
const message = {
searchResults: searchEngine.search(searchTerm)
};
cache[searchTerm] = message;
//self.postMessage is the api for sending messages to main thread
self.postMessage(message)
}
/*self.onmessage is where we define the handler for messages recieved
from the main thread*/
self.onmessage = function(e) {
const {data, searchTerm} = e.data;
/*We can determine how to respond to the .postMessage from
SearchResults.js based on which data properties it has:*/
if(data) {
initiateSearchEngine(data)
} else if(searchTerm) {
search(searchTerm)
}
}
可以看到,我还加了些额外的代码。这里我加了缓存,这样之前搜索过的searchTerms就可以立即返回结果了。如此一来,最耗性能的用户交互(常按删除键)的效率就提高了。
我们来看看运行情况:
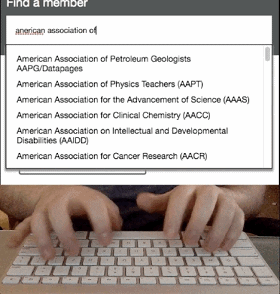
太棒了……非常快!这看起来很不错啊,实话说,做到这个样子就可以直接发布了!
但是,现在就发布多没劲啊……
从用户体验的角度来说,这个UI已经非常好了。如果仔细观察,其实依然能看到搜索结果的延迟,但几乎察觉不到……不过幸运的是,从性能测试报告中可以看到低效率的地方:
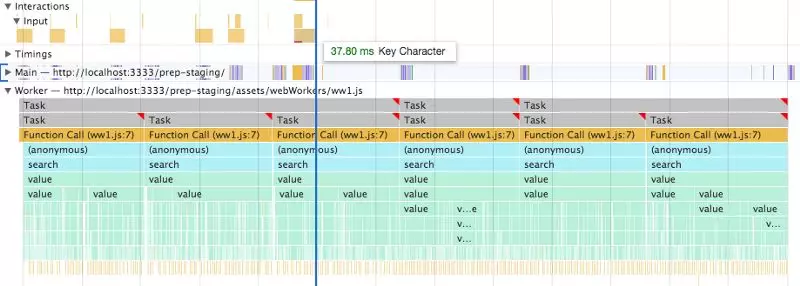
请无视灰色的条,我也不知道它们是怎么来的。
报告中最左侧的线程是我们关注的线程。Main线程已经折叠了,因为里面只有大量的空白,意味着主线程的性能非常好,不会成为任何主要的性能瓶颈。
可以看到,Worker线程里堆满了search调用。从最后一个Key Character输入(蓝线位置)之后就会看到其后果。Worker线程中的最后一个search实际上推迟了3个search才返回。测量一下会发现,延迟大约有850毫秒。而且大部分都是不必要的,因为那三个search都没用,我们不再需要它们返回的结果了。
你也许在想:“这已经很好了!再优化下去性价比不高啊!”
我不这样认为。首先,不要低估尝试新事物和探索带来的价值。如果你从来没做过探索,就很可能无法评价是否值得,因为你不知道你能有哪些收获,以及你将投入多少时间和努力。所以,我认为这种探索带来的经验和知识是无价的。随着知识的积累,你能更好地评价投入的时间是否值得,以及是否应该考虑这些问题。你可以做出更好的决定!
其次,别忘了这并不是过早优化。这些优化都是根据性能评价做出的,我们可以测量出效果。不管怎样评价,如果能改善850毫秒的延迟,那都是非常重大的改进。
最后(但不是唯一),别忘了移动端!虽然我不会在本文中介绍,但我在研究这个问题时,我也跟踪了移动端的性能,现在的条件下依然有能察觉得到的性能延迟。
不管怎么说,我们来解决这个问题!
第七篇 确保searchTerm
前面的性能评测揭示的最明显的问题就是,即使对于无用的searchTerm也会运行昂贵的搜索。所以目前的解决方案之一就是在执行昂贵的搜索之前确保searchTerm是最新的。只要在webWorker脚本中加入confirmSearchTerm就可以非常容易地实现:
//webWorker.js
self.importScripts('...the search engine script, provides the SearchEngine constructor');
let searchEngine;
let cache = {}
function initiateSearchEngine (data) {
searchEngine = new SearchEngine(data);
cache = {};
}
function search (searchTerm) {
const cachedResult = cache[searchTerm]
if(cachedResult) {
self.postMessage(cachedResult)
return
}
const message = {
searchResults: searchEngine.search(searchTerm)
};
cache[searchTerm] = message;
self.postMessage(message)
}
function confirmSearchTerm (searchTerm) {
self.postMessage({confirmSearchTerm: searchTerm})
}
self.onmessage = function(e) {
const {data, searchTerm, confirmed} = e.data;
if(data) {
initiateSearchEngine(data)
} else if(searchTerm) {
/*check if the searchTerm is confirmed, if not, send a confirmSearchTerm message
to compare the searchTerm with the latest value on the main thread */
confirmed ? search(searchTerm) : confirmSearchTerm(searchTerm)
}
}
这里还给SearchResults handleResults加了个额外的条件,监听confirmSearchTerm的请求:
//searchResults.js
export default class SearchResults extends React.Component {
constructor (props) {
super();
this.state = {
searchResults: [],
}
this.webWorker = new Worker('...path to webWorker.js')
this.webWorker.postMessage({data: props.data})
this.webWorker.onmessage = this.handleResults
}
componentDidUpdate(prevProps) {
const {searchTerm} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
this.webWorker.postMessage({searchTerm})
}
}
handleResults = (e) => {
const {searchResults, confirmSearchTerm} = e.data;
/* check if confirmSearchTerm property was sent, if so compare it to the
latest searchTerm and send back a confirmed searchTerm message */
if (confirmSearchTerm && confirmSearchTerm === this.props.searchTerm) {
this.webWorker.postMessage({
searchTerm: this.props.searchTerm,
confirmed: true
})
} else if (searchResults) {
this.setState({
searchResults
})
}
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
}
我们来看看性能评测,看看有没有改进:
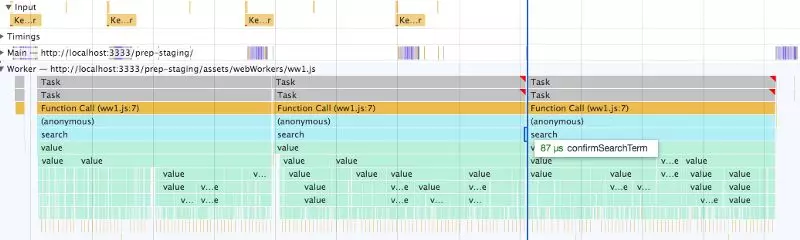
很难看出结果,因为它们运行得太快了,但在每次Worker的执行栈之前都会执行confirmSearchTerm(见蓝线)。
说明的确管用了:Worker在每次运行昂贵的search方法之前都会确认搜索是否必要。而且可以看到,顶部的橙色部分有4个Key Character输入,但只运行了三个搜索。这里我们成功地去掉了一个不必要的搜索,节约了最多330毫秒。但之前我们看到,多个额外的搜索会进入队列然后再不必要地运行,而现在我们完全避免了这个问题。所以,节约的时间非常显著,特别是在移动端上。
但仔细观察就会发现我们依然在浪费时间:
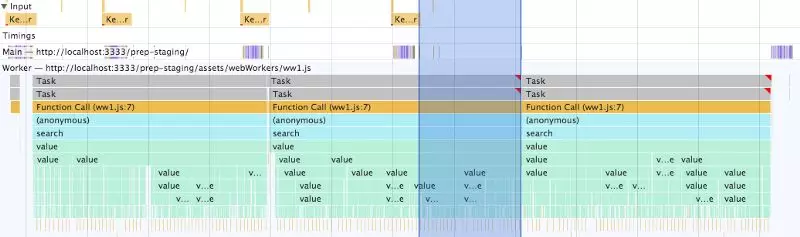
最后一个搜索使用了最新的searchTerm,但依然要至少等待当前的搜索完成后才能开始。浪费了84毫秒(蓝色高亮部分)!据我所知,执行栈一旦开始就无法取消。那么我们是不是无计可施了呢?
第八篇 Web Worker阵列
如果多加一个线程的效果很好,那么加4个会怎样?
实话实说,现在这些只是出于兴趣……但说真的,最后这次优化确实在移动端上带来了人眼能察觉到的改善……
无论怎样,现在我打算用Web Worker阵列!
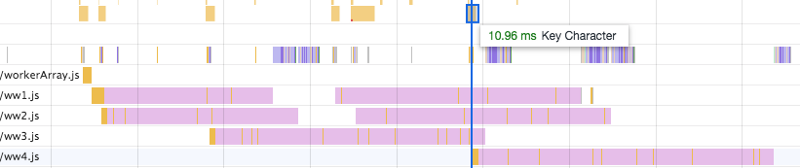
为了出这份报告,我用人类最快的速度输入的!
图中可以看到,顶端每个橙色的Key Character都有一个ww worker线程,能立即开始搜索(橙色条)。不再需要等待前一个搜索结束。而且每个ww在结束后就能用于下一次搜索。
这是因为我们设置了workerArray.js这个web worker作为分发器。图中看不到,因为它执行得太快了,但对于每个Key Character,workerArray都会执行一个微笑的执行栈,用来处理主线程传来的搜索请求消息,然后分发给第一个可用的ww worker。
我们成功地解决了“搜索堆”的问题。可以认为用增加车道的方式解决了交通拥堵。
为什么用4个搜索worker呢?因为我在测试时的输入速度从来没能到过需要第五个worker的速度(增加worker带来的改进非常微小)。
结果发现,从Key Character输入到search执行之间没有任何延迟。除非找到另一个更有效的搜索算法,否则我们已经成功地移除了所有性能瓶颈。
别忘了,我并没有说这是最佳的解决方案。是否每台手机都能处理4个web worker?性能改善是否值得付出这些额外的代码复杂度?是否还有其他安全方面的考量,导致代码更加复杂?
这些问题都非常重要,正是这些问题会最终引出这样的解决方案。
但至少现在,这个Web worker阵列非常优秀!我们来看看实际效果:

感谢你耐心地阅读完所有的篇节!
如果说这一系列优化有什么感想的话,那就是:
- 不要害怕尝试新事物,不要害怕不寻常的方案。
- 方案是否好用并不重要,它们带来的经验和知识才是最有价值的!
如果你有兴趣,可以看看下面Web worker阵列的代码。
课外作业
下面的代码中有个小问题。需要一个非常微小的修改才能使它更强壮,最多两行代码。你能找到问题所在并修复吗?
//searchResults.js
export default class SearchResults extends React.Component {
constructor (props) {
super();
this.state = {
searchResults: [],
}
//initiate the worker array:
this.workerArray = new WorkerArrayController({
data: props.data,
handleResults: this.handleResults,
arraySize: 4
});
}
componentDidUpdate(prevProps) {
const {searchTerm} = this.props;
if(searchTerm && searchTerm !== prevProps.searchTerm) {
this.workerArray.search({searchTerm})
}
}
handleResults = (e) => {
const {searchResults} = e.data
this.setState({
searchResults
})
}
componentWillUnmount () {
this.workerArray.terminate();
}
render () {
return <ReactVirtualizedList searchResults={this.state.searchResults}/>
}
}
SearchResults组件初始化WorkerArrayController。
//workerArrayController.js
export default class WorkerArrayController {
constructor ({data, handleResults, arraySize}) {
this.workerArray = new Worker('... path to workerArray.js');
let i = 1;
this.webWorkers = {};
while (i <= arraySize) {
const workerName = `ww${i}`;
this.webWorkers[workerName] = new Worker(`...path to ww1.js`);
/* Creates a MessageChannel for each worker and passes that channel's
ports to both workerArray dispatcher and the worker so
they can communicate with each other */
const channel = new MessageChannel();
this.workerArray.postMessage({workerName}, [channel.port1]);
this.webWorkers[workerName].postMessage({data}, [channel.port2]);
i++;
}
this.workerArray.onmessage = handleResults;
}
search = (searchTerm) => {
this.workerArray.postMessage({searchTerm});
}
terminate() {
this.workerArray.terminate();
for (const workerName in this.webWorkers) {
this.webWorkers[workerName].terminate();
}
}
}
WorkerArrayController用4个ww初始化workerArray web worker,并传递MessageChannel端口给它们,这样它们能够互相通信。
//workerArray.js
const ports = {};
let cache = {};
let queue;
function initiatePort (workerName, port) {
ports[workerName] = port;
const webWorker = ports[workerName];
webWorker.inUse = false;
webWorker.onmessage = function handleResults (e) {
const {searchTerm, searchResults} = e.data;
const message = {searchTerm, searchResults};
/* If all workers happen to be inUse, the message gets saved to the
the queue and passed to the first worker that finishes */
if(queue) {
webWorker.postMessage(queue);
webWorker.inUse = true;
queue = null;
} else {
webWorker.inUse = false;
}
cache[searchTerm] = message;
self.postMessage(message);
}
}
function dispatchSearchRequest (searchTerm) {
const cachedResult = cache[searchTerm];
if(cachedResult) {
self.postMessage(cachedResult);
return
}
const message = {searchTerm};
for (const workerName in ports) {
const webWorker = ports[workerName];
if(!webWorker.inUse) {
webWorker.postMessage(message);
webWorker.inUse = true;
return
}
}
queue = message;
}
self.onmessage = function (e) {
const {workerName, searchTerm} = e.data;
if(workerName) {
initiatePort(workerName, e.ports[0]);
} else if(searchTerm) {
dispatchSearchRequest(searchTerm);
}
}
workerArray初始化端口对象用于通信,并跟踪每个ww worker。它还初始化了缓存和队列,万一所有端口都被占用的情况下用来跟踪最新的searchTerm请求。
//ww1.js
self.importScripts('...the search engine script, provides the SearchEngine constructor');
let searchEngine;
let port;
function initiate (data, port) {
searchEngine = new SearchEngine(data);
port = port;
port.onmessage = search;
}
/* search is attached to the port as the message handler so it
runs when communicating with the workerArray only */
function search (e) {
const {searchTerm} = e.data;
const message = {
searchResults: searchEngine.search(searchTerm)
};
port.postMessage(message)
}
/* self.onmessage is the handler that responds to messages from
the main thread, which only fires during initiation */
self.onmessage = function(e) {
const {data} = e.data;
initiate(data, e.ports[0]);
}
原文:Secrets of JavaScript: A tale of React, performance optimization and multi-threading
